Gathering literature and ways to store them are very personal. Some people prefer to do it manually, over paper and pen; with marks, scribbles, highlights or even coffee spill from the favourite cafe. Some other use software, either EndNote or other words processing software.
I place myself somewhere in between. I usually prefer to look at hardcopies when I encountered a new topic, or wanting to sit on a fancy café. Also the other reason is that I like to have a printed bibliography of the new ideas.
When I did my master degree’s dissertation, I used MS Word. I created files based on a theme or identified topic. Before I started my PhD, I was sure that a better storing system is in order. Asked around, did not get satisfactory answers. My gut feeling told me that once I hit 100 references, it will be quite a stretch to manage them. Never mind for the whole PhD duration. I thought “It is a simple concept, like hashtag system. Categorising based on a hashtag, and at the same time we can view information filed under a certain tag. There should be something out thereâ€. In my fourth month, I found Nvivo which is a CAQDAS (Computer-Assisted Qualitative Data Analysis Software) and used it ever since to manage my library.
Although it took me a while to figure out, using Nvivo as means to storage literature is not new. QSR International provides webinars, e-demos and tutorials which guide us from the scratch, I suggest to check their resources.
Here are my usual steps:
- Find the intended reference, download the reference management format
- Open EndNote and import downloaded file in EndNote
- If the reference is in form of softcopy, attached pdf in EndNote data
- If is in form of hardcopy, I usually use my OCR pen to transfer data to editable text. Or simply re-type the text
- In EndNote, export file(s) to .xml format
- Open Nvivo, import it
- Categorise them accordingly in Nodes
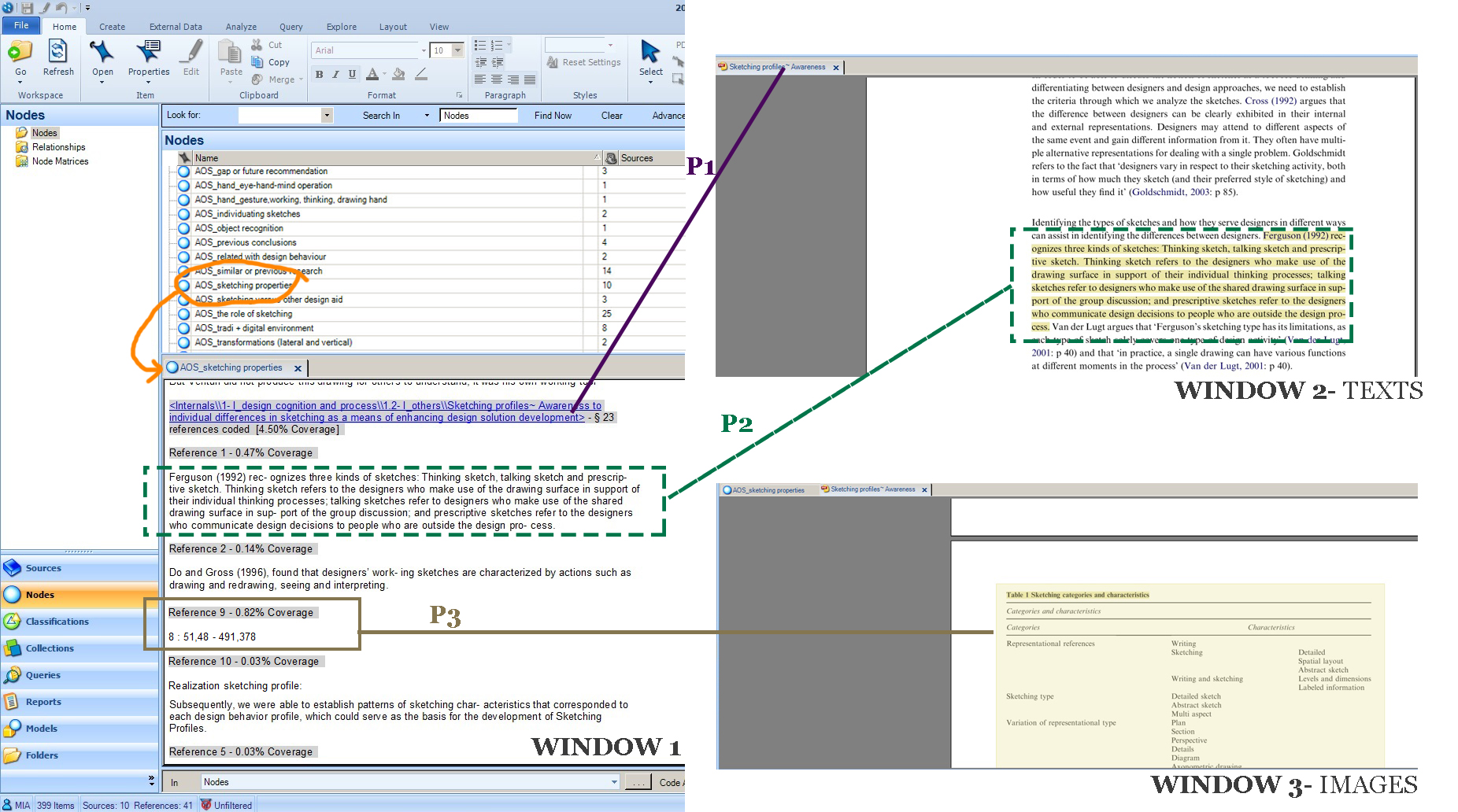
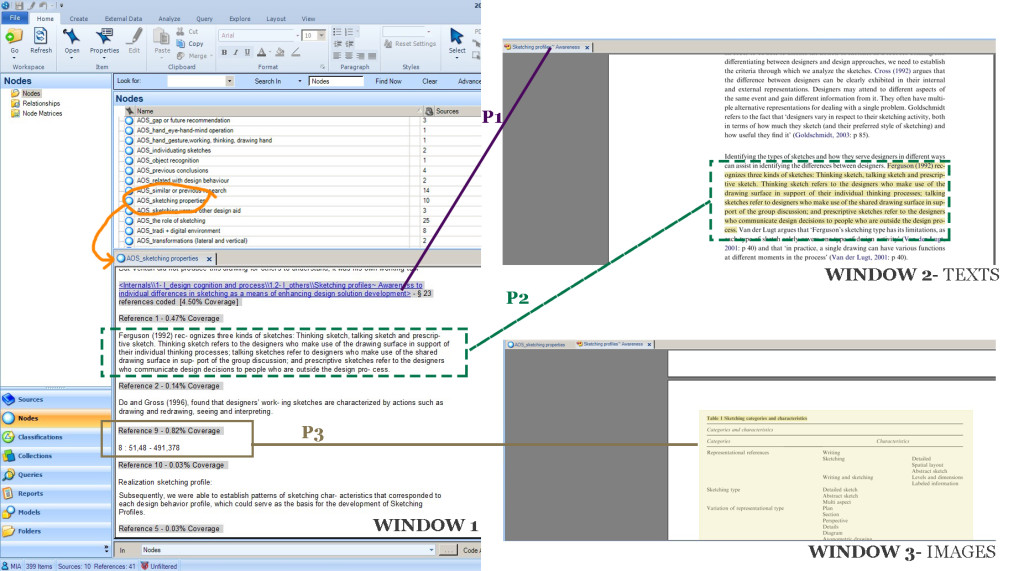
In Window 1, there is a long list of nodes I took from my own Nvivo file. The orange colour highlight shows a node I choose to illustrate, “AOS_sketching profile†node. At the bottom bit is what we see when we click the node. Identical idea with hashtags, everything I labelled previously can be found in the node. If we want to see more of a context of the text, click on the underlined words (title of the article)- refer to P1.
It shows Window 2, where exactly the passages are in relation with the whole article- refer to P2. Similarly if we have coded an image, it will direct us to the image- Window 3 . Right click on the location of the image (in my illustration, refer to P3 8 : 51,48 – 491,378 )>Links>Open references source; and it will take us to the image.
Nvivo is quite handy and aids me to focus more on a topic. Words can be coded, un-coded or changed to other codes easily. What needs an improvement (or perhaps what I need to find out) from this system is references in a Node are arranged alphabetically. It would be great that they can be arranged based on the year of publication, so that it’s easier to identify the flow of debates. Also one thing is very crucial, based on my experience, the software has been a great help to arrange my references; BUT doing analysis is our job and not the software.
This is just a brief explanation about using Nvivo to store and manage reference. I am no where near an expert, you are more than welcome to drop me a message to say Hi and possibly bounce some ideas back. Bye for now.